I've been doing a bit recently around DevOps and what I've been seeing is that companies that having been scaling DevOps tend to run into a problem: exactly what is a good boundary for a DevOps team? Now I've talked before about how Microservices are just SOA with a new logo, well there is an interesting piece about DevOps as well, its not actually a brand new thing. Its an evolution and industrialisation of what was leading practice several years ago.
Back in 2007 I gave a presentation on why SOA was a business challenge (full deck at the end) and in there were two pictures that talked about how you needed to change the way you thought about services:
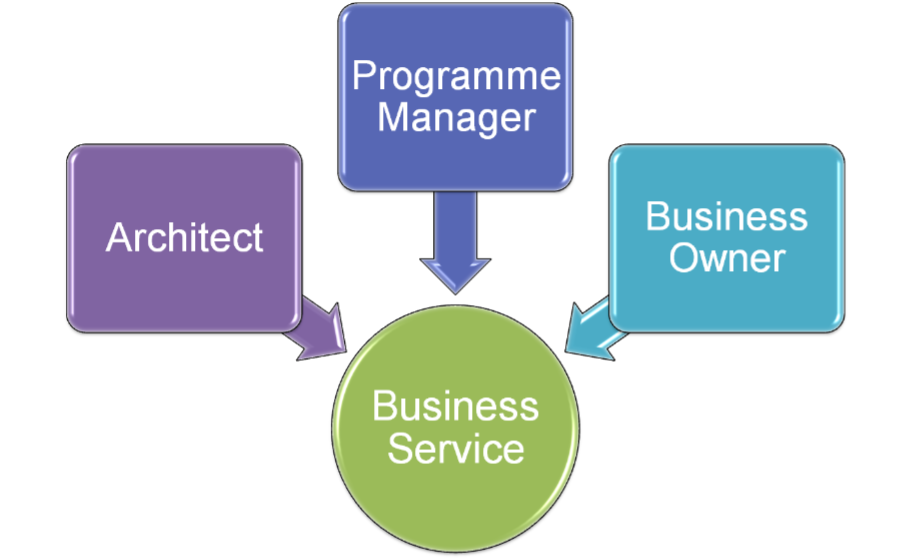
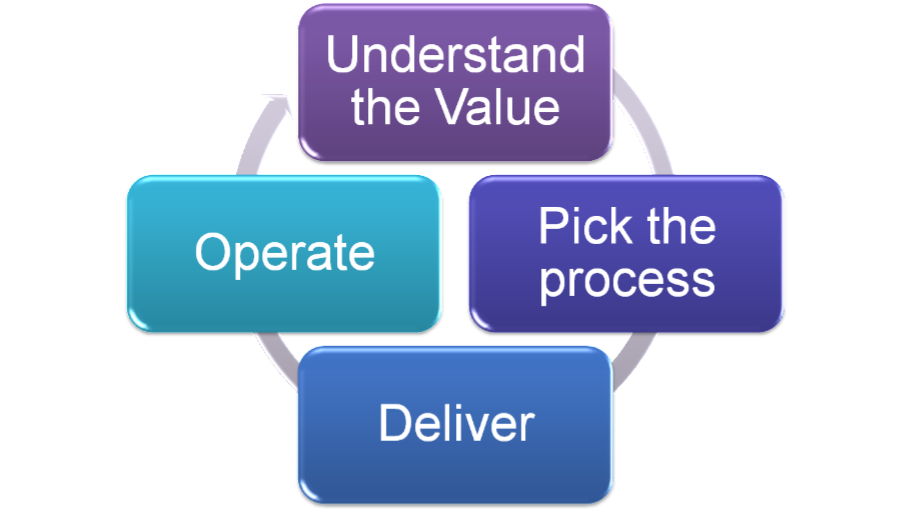
So on the left we've got a view that says that you need to think about a full lifecycle, and on the right you've got a picture that talks about the needs to have an architect, owner and delivery manager (programme manager)
This is what we were doing around SOA projects back in 2007 as a structure and getting the architects and developers (but ESPECIALLY the architects) to be accountable for the full lifecycle. Its absolutely fantastic to see this becoming normal practice and there are some great lessons out there and technical approaches.
One thing I've not seen however is an answer to what my DevOps team is and how I manage a large number of DevOps teams. This is where Business Architecture comes in, the point here is that its not enough to just have lots and lots of DevOps teams, you need to align those to the business owners and align them to the structure that is driving them. You also need to have that structure so one team doesn't just call the 'Buy from Ferrari' internal service without going through procurement first for approval.
So in a DevOps world we are beginning to realize the full-lifecycle view on Business Services, providing a technical approach to automating and managing services that look like the business, evolve like the business and provide the business a structure where they can focus costs where it delivers the most value.
There is much new in the DevOps world, but there is also much we can learn from the Business Architecture space on how to set up DevOps teams to better align to the business and enable DevOps to scale at traditional complex organisations as well as more simple (from a business model perspective) internet companies.
Back in 2007 I gave a presentation on why SOA was a business challenge (full deck at the end) and in there were two pictures that talked about how you needed to change the way you thought about services:
So on the left we've got a view that says that you need to think about a full lifecycle, and on the right you've got a picture that talks about the needs to have an architect, owner and delivery manager (programme manager)
This is what we were doing around SOA projects back in 2007 as a structure and getting the architects and developers (but ESPECIALLY the architects) to be accountable for the full lifecycle. Its absolutely fantastic to see this becoming normal practice and there are some great lessons out there and technical approaches.
One thing I've not seen however is an answer to what my DevOps team is and how I manage a large number of DevOps teams. This is where Business Architecture comes in, the point here is that its not enough to just have lots and lots of DevOps teams, you need to align those to the business owners and align them to the structure that is driving them. You also need to have that structure so one team doesn't just call the 'Buy from Ferrari' internal service without going through procurement first for approval.
So in a DevOps world we are beginning to realize the full-lifecycle view on Business Services, providing a technical approach to automating and managing services that look like the business, evolve like the business and provide the business a structure where they can focus costs where it delivers the most value.
There is much new in the DevOps world, but there is also much we can learn from the Business Architecture space on how to set up DevOps teams to better align to the business and enable DevOps to scale at traditional complex organisations as well as more simple (from a business model perspective) internet companies.







